
Shifting Consumption towards Diverse Content on Music Streaming Platforms (WSDM’21, 링크)
1. 풀고싶은 문제
- 음악 스트리밍 플랫폼에서 추천 모델을 통해 유저들이 다양한 콘텐츠 소비를 하게끔 유도하고 싶다.
- 보통 satifaction metric(논문에서는 Relavance로 정의)과 diversity 간에는 trade-off가 있는데
- Ranking model의 complexity가 높아질 때 trade-off가 어떻게 형성되는지 알고 싶다.
- Scoring 할 때 어떤 방식으로 diversity를 고려해야 좋을지 알고 싶다.
2. 이 문제가 왜 중요한가
유저 측면: 다양성이 높아지면 Filter bubble, Popularity Bias를 피할 수 있다.
플랫폼 측면: 음악 장르를 다양하게 소비하는 유저일수록 conversion이나 retention이 높다. [1]
음악 산업 생태계 측면: 덜 유명한 노래의 노출이 는다. 다양한 음악이 기회를 얻음으로써 건강한 생태계가 유지된다.
3. 문제를 어떻게 풀었는가
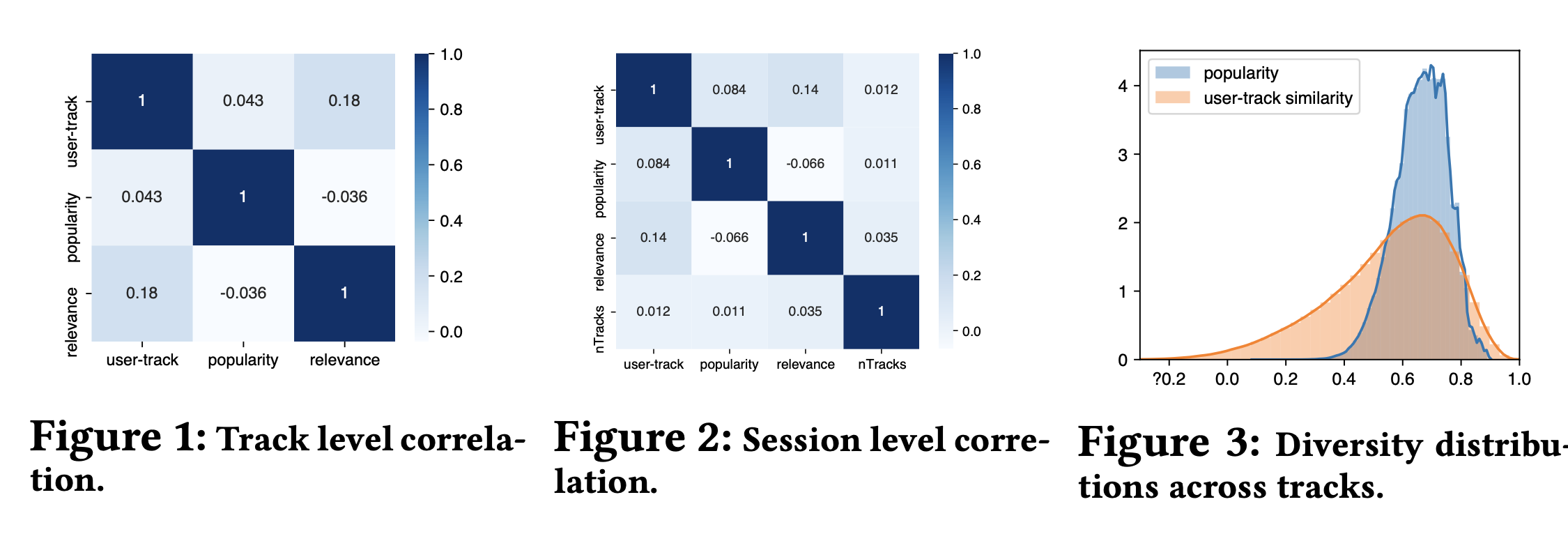
Quantify Diversity Metrics
- 덜 유명한 노래를 들을수록(popularity) 값이 높아지는 diversity metric과
- 유저가 평소 취향과 덜 비슷한 노래를 들을수록(user-track similarity) 값이 높아지는 diversity metric을 각각 만들었다.
- popularity는 글로벌하게 정의되는 지표고 user-track similarity는 개인에게 정의되는 지표다.
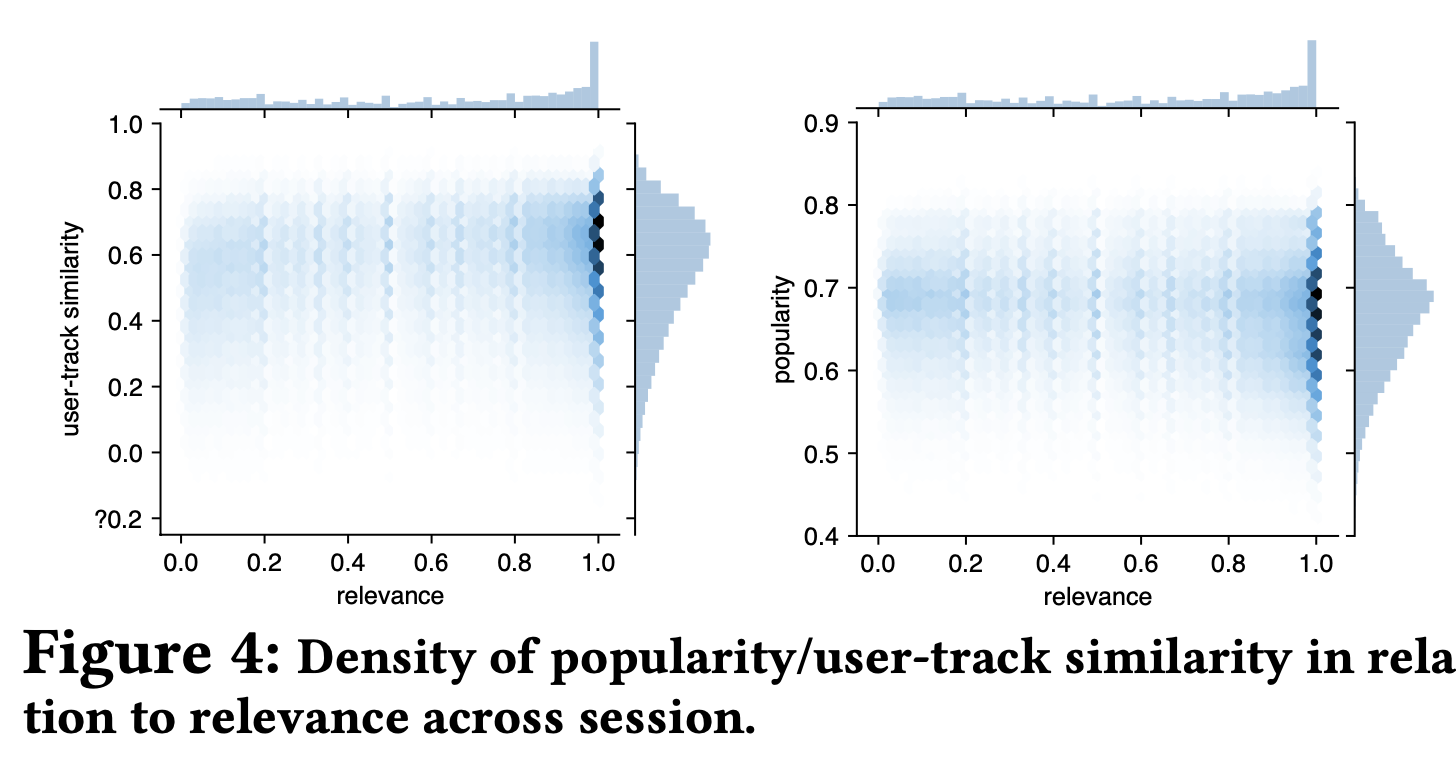
- 두 가지 diversity meric과 relevance 간의 correlation과 distribution을 조사해보았더니 다양성을 고려한 추천을 하더라도 유저의 만족도를 해치지 않을 가능성을 확인했다.
Ranking Model
 Chill Vibes 플레이리스트의 곡들을 맞춤형 순서로 정렬하고 있다. 유저가 스킵하지 않고 들은 노래가 위에 있을수록 HitRatio나 NDCG가 높아진다.
Chill Vibes 플레이리스트의 곡들을 맞춤형 순서로 정렬하고 있다. 유저가 스킵하지 않고 들은 노래가 위에 있을수록 HitRatio나 NDCG가 높아진다.
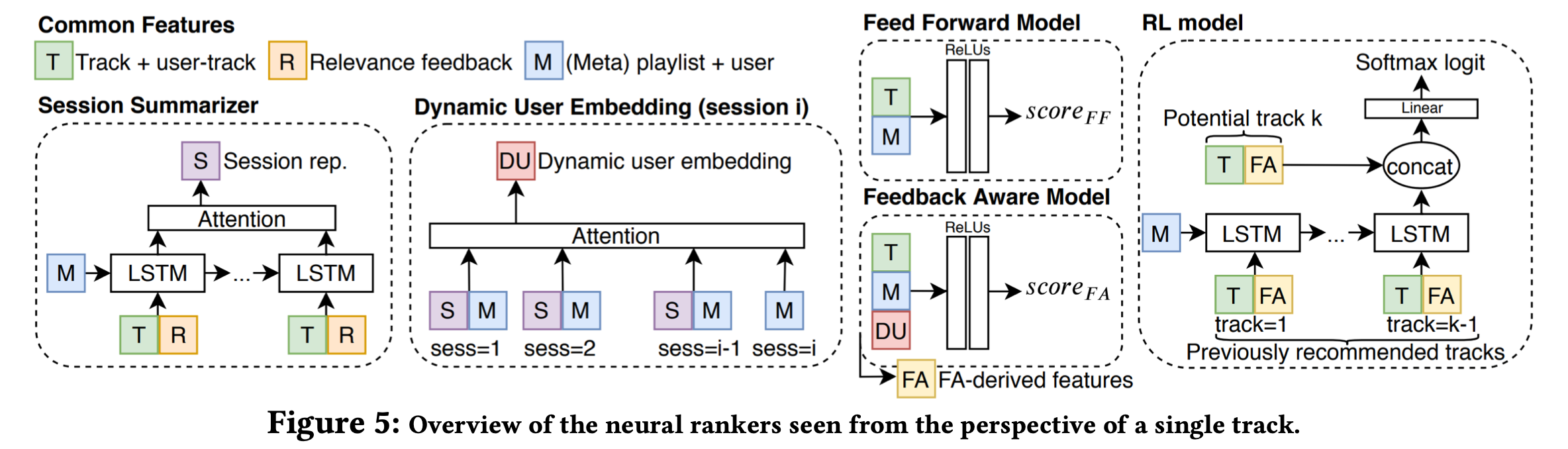
아래 네 가지 Ranking Model을 사용하여 모델 Complexity가 높아질 때 Diversity와 Relavance의 Trade-Off가 어떻게 변하는지 관찰했다.
- Cosine Ranker: User벡터와 Track벡터의 Cosine Similarity가 높은 트랙에 높은 Score를 준다
- Feedforward Ranker: Feed forward Network 두 개를 붙인 간단한 구조. Skip 여부가 label로 들어간다.
- Feedback aware Ranker : 1) Session Summarizer 2) Dynamic user embedding이 도입된 모델. (그림 참조)
- RL Ranker: Feedback aware Ranker 에서 파생된 Feature를 State Representation으로 사용하는 REINFORCE 모델. $\pi(t\mid s)$ (← State가 주어졌을 때 Track을 Sample할 확률)을 학습한다. Reward로는 relevance만 고려할 수도 있고 diversity를 추가로 고려할 수도 있다.
Diversity를 반영한 Scoring
지도학습 모델의 경우 모델을 고정하고 1~3의 방법으로 Scoring하여 Trade-Off를 살펴본다.
RL model의 경우 Reward에 diversity를 반영한다.
- Linear Interpolation: 모델 아웃풋 값과 Diversity Score를 weighted sum하는 방식
- Submodular: 모델 아웃풋 값과 Diversity Score를 조합하여 submodular한 함수로 만들어서 이 함수로 Scoring하는 방식
- Interleaving: R모델 아웃풋 값 순으로, Diversity Score순으로 리스트를 각각 만든다음 $1-\alpha$ 의 확률로 각 리스트에서 샘플하는 방식
- RL model: RL Ranker의 경우 다음 Reward function을 사용하는 방식
$$ R(t, s)=r(t, u)-c+\alpha d(t, u) r(t, u) $$
4. 실험 셋팅, 결과
실험 셋팅
- RL 모델(REINFORCE)의 경우 propensity score 데이터가 로깅되지 않아서 off-policy learning을 할 수 없었다. 다른 연구를 참고하여 simulator를 만들어서 학습했다.
- 학습 데이터로 5개 이상의 세션이 있는 유저를 골랐고 5트랙 이상 청취기록이 있는 세션만 골랐다.
- diversity pool을 충분히 확보하고자 하는 취지에서 평가에서는 25track 이상 있는 플레이리스트만 골랐다.
- session의 첫 번째 곡은 relevance 기준으로만 선택된다. 이후에는 diversity metric도 같이 고려하여 추천한다.
실험 결과
Q1) model complexity가 높아질 때 trade-off가 어떻게 형성되는지 알고 싶다.
Diversity를 고려하지 않고 Scoring 했을 때 결과

- Complexity가 높아질수록 Relavance(HR, NDCG)가 높아졌지만
- 평균 Popularity와 Similarity가 높아짐을 확인했다.
- Cosine 모델은 Similarity순으로 Ranking을 매기는 방식이므로 User-track Similarity가 제일 높을 수 밖에 없다.
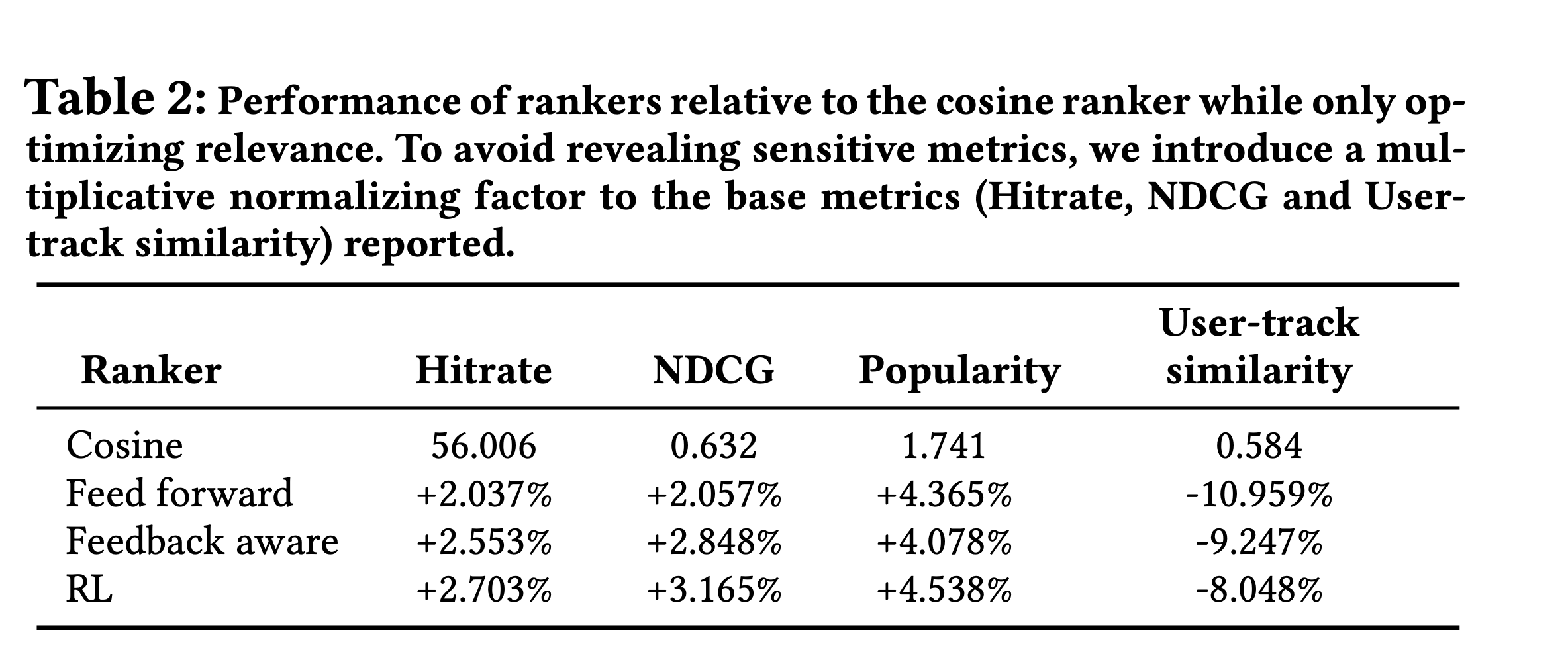
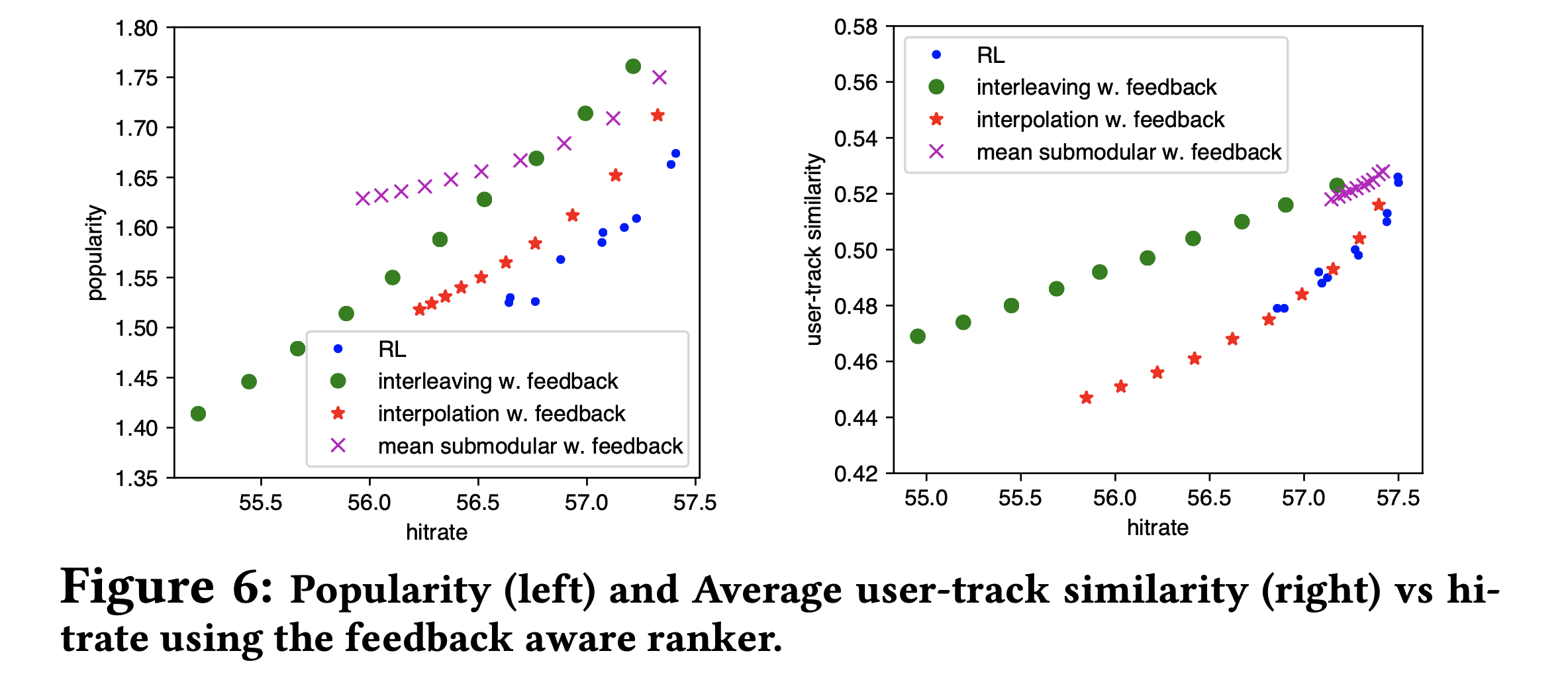
Diversity를 고려하여 Scoring 했을 때 결과 (Feedback Aware모델만 제시한 그림)
- 같은 색의 다른 점들은 diversity 관련 하이퍼파라미터를 조정하면서 생긴 값들이다.
- 같은 HitRate일 때 Popularity와 Similarity가 낮을 수록 좋으므로 오른쪽 아래로 갈 수록 좋은 trade-off를 가진 모델로 볼 수 있다.
- Feedback Aware모델의 경우 Interpolation 방식이 제일 Trade-Off가 좋았다.
- 심지어 User-Track Similarity의 경우 RL모델과 비슷한 정도의 trade-off를 냈고 range가 넓어 system designer에게 더 많은 선택권을 줄 수도 있다.
Q2) Consumption Shift이 일어났는가?
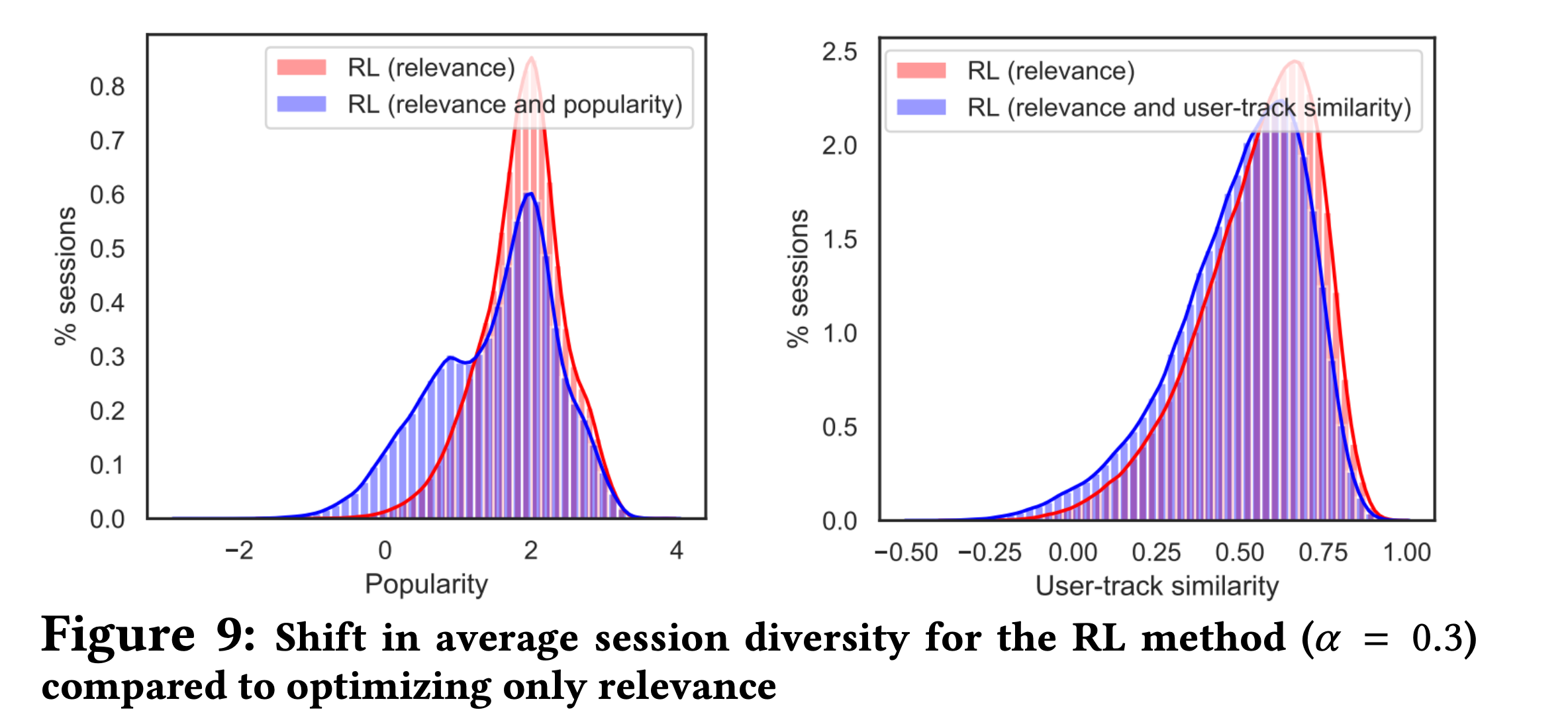
- Relavance만 Reward에 고려한 모델보다 Diversity를 Reward에 더한 모델의 분포가 Diversity관점에서 좋았다.
5. 후속 연구 방향
- REINFORCE 학습을 Simulator대신 Off-policy Training 하겠다.
- 유저마다 diverse한 콘텐츠에 반응하는 정도가 (색다른 콘텐츠를 시도해보는 정도가) 다르다. 유저마다 diverse한 정도를 personalize하는 연구를 해보자. (user-aware)
- Reward 모델링을 더 풍부하게 짜보자.
6. 자유 리뷰, 궁금점
서비스에서 Diversity를 얼마나 중요하게 여기느냐에 따라 이 연구의 가치나 중요도가 다르다. 스포티파이는 Diversity와 관련된 연구를 계속 내놓는 것을 미루어 보아 Diversity의 실질적인 가치를 높게 평가하는 걸로 보인다. 다른 도메인이나 서비스에서도 중요할까는 각자 다시 확인해봐야 할 테다. 음악 도메인이니까 또는 해외 문화권이니까 Diversity가 주요 Metric으로 판명되지는 않았는가? OTT서비스라면 또는 국내 음악 서비스인 멜론이라면 중요하지 않을 수도 있다.
논문의 주장대로 Diversity와 Relavance가 Trade-Off 관계라면 의사결정권자는 어느 정도의 Trade-Off를 감당할지 정해야 하는데 Diversity를 얼마나 중요시 하느냐에 따라 다른 결정을 하지 않을까. 혹시 Diversity와 Relavance를 같이 늘릴 수 있는 방법은 없을까.
방법론 측면에서 세세한 부분에 궁금점이 있다. $d(u, t)$ 는 구체적으로 어떻게 만들었을지, Session Summarizer에서 Meta Info를 Initialize에 사용하는게 어떤 의미이고 유용할지, Interaction vector를 만드는 방식(논문에서 수식 (4) 내용)은 왜 그렇게 만들었고 어떤 효과가 있을지 궁금하다.
참고자료
[1] shton Anderson, Lucas Maystre, Rishabh Mehrotra, Ian Anderson, and Mounia Lalmas. 2020. Algorithmic Effects on the Diversity of Consumption on Spotify. In The World Wide Web Conference