
ELWC protobuf 구조를 이해하고 ELWC 구조의 데이터를 TF-Ranking으로 읽습니다.
Learning To Rank(LTR) 문제 정의
LTR는 아이템 리스트가 입력으로 주어졌을 때 관련도 순서대로 리스트를 정렬하는 함수를 만드는 문제다. 주로 검색, 추천, Question & Answering 분야에서 활용하고 있다. 검색의 경우 유저가 질의하면 여러 후보 문서 중에 관심 있어할 문서의 랭킹을 높여 상단에 노출하는 문제로 볼 수 있다. 음악 추천 문제의 경우 유저의 청취 기록을 바탕으로 관심 있어할 노래를 앞 순서에 배치하여 유저에게 보여주는 문제로 볼 수 있다.
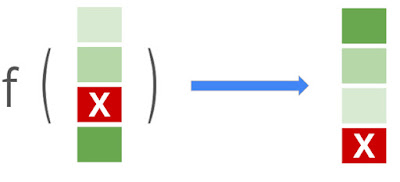 색이 진한 아이템 관련도가 높음을 의미고 X 표시된 아이템은 관련없음을 나타낸다.
색이 진한 아이템 관련도가 높음을 의미고 X 표시된 아이템은 관련없음을 나타낸다.
(출처 : https://ai.googleblog.com/2021/07/advances-in-tf-ranking.html)
Tensorflow Ranking(TF-Ranking)은 구글에서 LTR 문제를 머신러닝으로 풀기 위해 만든 라이브러리이다. LTR 문제에서 자주 사용되는 모델, Loss, Metric을 Tensorlfow와 호환되도록 제공한다. 이 글에서는
1
2
- TF-Ranking에서 주로 사용하는 ExampleListWithContext(ELWC) protobuffer를 살펴보고 왜 ELWC를 선택했는지 알아본다.
- 실습 예제로 TFRecord로 저장된 Question-Answering 데이터셋 ANTIQUE를 TF-Ranking을 이용하여 읽어본다.
Protocol Buffer, TFRecord, tf.train.Example
ELWC를 이해하려면 Protocol Buffer(protobuf)와 TFRecord의 기본적인 내용을 알고 있어야 한다. protobuf는 구글에서 개발한 이진 포맷이다. TF Serving의 통신 수단인 gRPC에서 사용한다. TFRecord는 Tensorflow를 위해 설계된 이진 포맷이다. TFRecord는 보통 protobuf로 직렬화된 데이터를 담고있다. protobuf의 객체는 아래 코드와 같이 message로 정의한다. 필드에는 자료형을 나타낸 다음 식별자(코드에서 1, 2, 3)을 적어준다. Tensorflow에서 사용하는 protobuf message는 tf.train.Example이다. Example message는 하나의 Features message로 구성된다. 자세한 내용은 튜토리얼을 참고하자.
1
2
3
4
5
6
7
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
ELWC - Example List와 Context가 결합된 message
LTR 데이터를 표현하기 위해서는 두 가지가 고려되어야 한다.
1) Ranking을 매겨야 하는 아이템 리스트는 주로 Context와 함께 주어진다. 검색의 경우 (검색어, 검색하는 장소, 검색하는 기기) 등등이 Context가 될 것이다. 때문에 Context가 데이터에 같이 표현되어야 한다.
2) Ranking을 매겨야 하는 아이템 리스트는 두 개 이상인 경우가 많고 길이가 가변적이다. “tensorflow”를 검색했을 때 Ranking을 매겨야 하는 아이템의 수가 “ELWC”를 검색했을 때의 아이템 수가 같지 않을 것이다. 때문에 가변 개수의 아이템이 표현되어야 한다.
TF-Ranking에서는 이런 점을 고려하여 ELWC message를 주 데이터 포맷으로 사용한다. ELWC는 아래처럼 정의되어 있다.
1
2
3
4
message ExampleListWithContext {
repeated tensorflow.Example examples = 1;
tensorflow.Example context = 2;
}
TF-Ranking으로 ANTIQUE 데이터 읽기
ANTIQUE: A Non-Factoid Question Answering Benchmark는 Yahoo! Answers에서 수집한 Question-Answering 데이터이다.(Yahoo! Answers는 21년 5월에 서비스를 종료했다.) 이곳에서 ELWC 메시지 tfrecord 형태로 저장된 데이터를 받을 수 있다. TR-Ranking에서 고수준의 모델 학습 파이프라인을 지원하기 때문에 파일 경로만 지정해도 학습이 가능하지만 어떤 데이터가 저장되어있는지 눈으로 확인하고 싶었다. 이진 포맷으로 저장되어 있기 때문에 parsing을 해야 사람이 읽을 수 있는데 이 방법이 꽤 까다롭다.
 TF-Ranking의 Workflow (출처 : https://ai.googleblog.com/2021/07/advances-in-tf-ranking.html)
TF-Ranking의 Workflow (출처 : https://ai.googleblog.com/2021/07/advances-in-tf-ranking.html)
라이브러리에서 제공하는 예제 코드를 데이터 읽는 부분만 잘라내서 코랩에 옮겨두었다. 코드 흐름을 살펴보면 ELWC로 직렬화된 데이터의 context_feature_spec과 example_feature_spec을 tfr.data.build_ranking_dataset에 제공해야 한다. 이 부분이 헷갈렸는데 데이터셋을 처음보는 사람이 데이터의 spec을 어떻게 알아낼 수 있는지 의아했다. 아마도 불가능할 것이고 데이터를 제공하는 사람이 스펙을 잘 적어줘야 하는게 아닐까 생각이 들었다.
데이터는 아래처럼 구성된다. ‘document_tokens’, ‘example_list_mask ‘, ‘query_tokens’가 key로 있는 Dict가 input으로 relevance가 label로 나온다.
- ‘document_tokens’, ‘query_tokens’가 가변길이를 처리하고 있기 때문에
RaggedTensor인 점을 확인할 수 있다. - 랭킹을 매겨야하는 아이템의 수가 다르기 때문에 길이가 다른 부분만큼 Padding처리가 된다. Padding된 부분은 ‘example_list_mask‘에서 False로 표시되고 label 부분에서 -1로 처리된다.
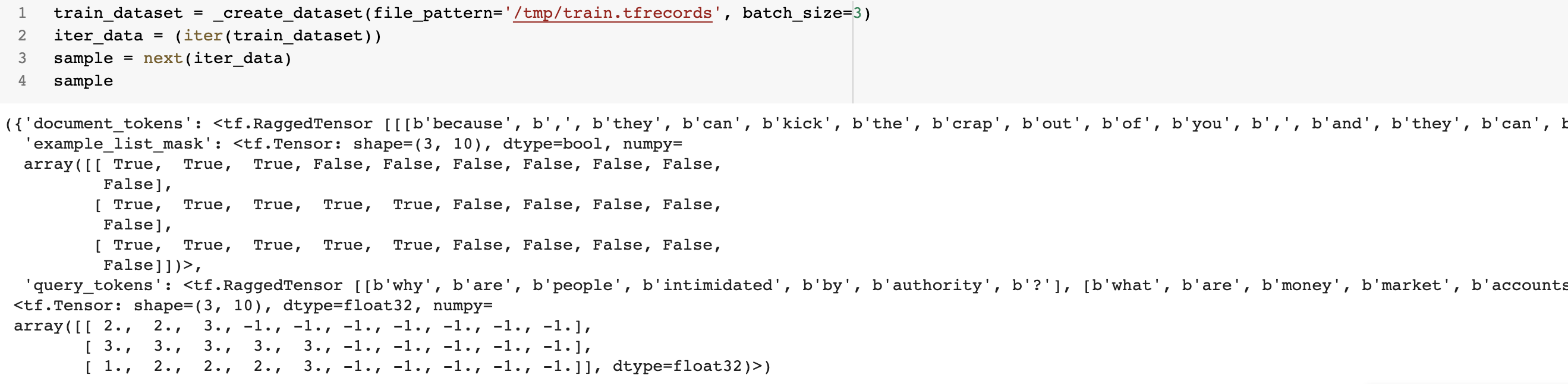
아래는 “why are people intimidated by authority?” 라는 쿼리에 “because , they can kick the crap out of you , and they can do whatever they want , fight them , and your wanted and you ##ll die” 라는 document의 relevance가 2점인 데이터다.

추가로 공부하면 좋을 내용
이 글에서는 TF-Ranking이 제공하는 기능을 전혀 다루지 않았다.
LTR을 공부하고 구현하기에 좋은 기능과 깔끔한 코드를 많이 제공해주고 있으므로 아래 내용들을 더 살펴보면 좋겠다.
- Ranking Metric 구현체. MRR, NCDG, Precision, MAP, Recall 등등 자주 쓰이는 Metric들이 구현되어 있다. 이때까지 직접 구현하여 사용했는데 이 코드를 활용하는 게 좋겠다. [Docs]
- Ranking에서 사용되는 Loss 이해하기. Ranking Metric은 index에 의해 값이 변하기 때문에 Discontinuous하고 Gradient Descent로 업데이트할 수 없는 경우가 많다. 때문에 미분 가능한 형태의 다양한 Proxy Loss들이 연구, 활용되고 있다. 데이터와 문제에 맞게 적절한 Loss를 선택할 수 있어야겠다. [Docs]
- LTR 모델 Baseline부터 SOTA 모델까지 살펴보기. 기존에는 Gradient Boosted Decision Tree(GBDT) 위주의 모델이 주로 연구되었지만 다른 분야와 마찬가지로 Neural Network 모델로의 연구로 흐름이 변해가고 있다. Neural Ranking모델이 Outperform한지는 아직 검증이 많이 필요해 보이지만 TF-Ranking에서는 GBDT 모델보다는 Neural Ranker 위주로 update해나갈 것으로 보인다. 기존 모델부터 두루두루 살펴보고 BERT를 Fine-Tuning해서 사용하는 예제까지 익혀보자.
참고자료
- Google AI Blog : Advances in TF-Ranking
- ICTIR 2019 Tutorial Slide : Neural Learning to Rank using TensorFlow
- TF-Ranking Github