
Eugene Yan의 원글을 허락받아 번역한 글입니다.
기업이 사용하는 추천과 검색 시스템 디자인은 어떨까요? 머신 러닝 논문이나 블로그에서 시스템 디자인을 이야기하는 경우는 드뭅니다. 대부분 모델 구조나 학습 데이터 또는 손실 함수를 다룹니다. 그럼에도 불구하고 시스템 세부 구현사항을 논의하는 몇몇 자료들이 있고 이들은 실전에서만 경험할 수 있는 디자인 패턴과 모범 사례를 설명합니다.
추천이나 검색과 같은 탐색 시스템에 한해서, 제가 접한 대부분의 구현이 비슷한 구조를 따릅니다. 구성 요소와 프로세스를 Offline과 Online 환경 그리고 Candidate Retrieval과 Ranking 단계로 나누어 볼 수 있습니다. 아래의 2 x 2 는 이것을 단순화한 도식입니다.
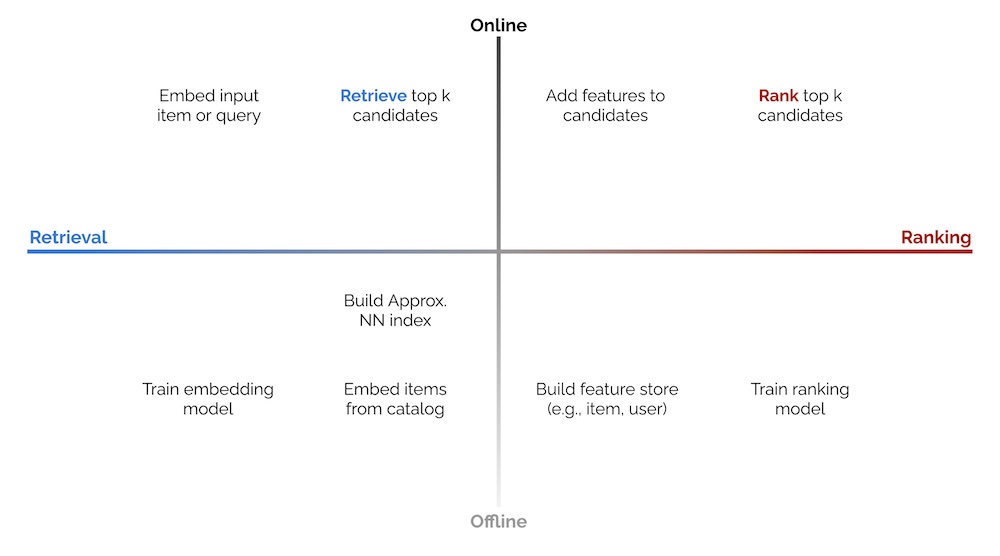 2 X 2 Online vs Offline 환경과 Candidate Retrieval vs Ranking
2 X 2 Online vs Offline 환경과 Candidate Retrieval vs Ranking
Offline 환경 에서는 모델 학습(예를 들어, representation learning, ranking), 아이템 카탈로그의 임베딩 생성, Approximate Nearest Neighbors(ANN) 인덱스 생성 또는 지식 그래프를 이용한 비슷한 아이템 찾기 같은 배치 프로세스를 주로 수행합니다. feature store에 아이템과 유저 데이터를 로드하는 과정이 필요할 수도 있습니다. 이는 ranking 단계 에서 인풋 데이터를 augment 할 때 사용됩니다.
Online 환경에서는 개별 request의 서빙을 위해 생성된 artifacts(e.g. ANN indices, knowledge graphs, models, feature stores)를 사용합니다. 일반적으로는 인풋 아이템 또는 검색 쿼리를 임베딩 값으로 바꾸고 candidate retrieval and ranking을 수행합니다. 전처리 단계(e.g. 쿼리 표준화, 토큰화, 철자 교정)가 있을 수도 있고 후처리 단계(e.g. 적절하지 않은 아이템 제거, 비즈니스 로직 수행)가 있을 수도 있습니다만 이번 글에서는 다루지 않겠습니다.
Candidate retrieval은 빠르지만 조악하게 수백만 개의 아이템에서 수백개의 후보로 좁히는 단계입니다. 다음 단계인 ranking을 적용할 범위를 빠르게 좁히기 위해 정밀도와 효율을 절충합니다. 대부분의 현대 retrieval은 인풋(e.g. 아이템 또는 검색어)을 임베딩으로 바꾼 다음 ANN을 이용하여 비슷한 아이템을 찾는 방식입니다. 그러나 아래의 예제에서 그래프를 이용하는 방법(DoorDash 사례)이나 decision tree를 사용하는법(LinkedIn 사례)도 살펴보겠습니다.
Ranking은 느리지만 정밀한 단계로 후보들을 점수 매겨서 순위를 매기는 단계입니다. 상대적으로 적은 아이템을 처리하기 때문에 retrieval 단계에서 latency나 연산량 제약으로 사용하기 어려웠던 feature들을 추가하여 사용할 여지가 있습니다. 이런 feature에는 아이템과 유저 데이터 또는 context 정보를 포함됩니다. 또한 더 많은 Layer와 parameter를 보유한 복잡한 모델을 사용할 수도 있습니다.
Ranking은 learning-to-rank 또는 분류 문제로 모델링 될 수 있지만 후자의 방식이 더 많이 보입니다. 딥러닝이 적용된다면 마지막 output layer에 아이템 카탈로그를 대상으로 하는 softmax를 사용하거나 유저-아이템 쌍의 interaction(e.g. 클릭이나 구매) likelihood를 예측하는 sigmoid를 사용합니다.
다음으로 위의 프로세스들이 추천과 검색 시스템에서 어떻게 함께 합쳐지는지 보겠습니다.
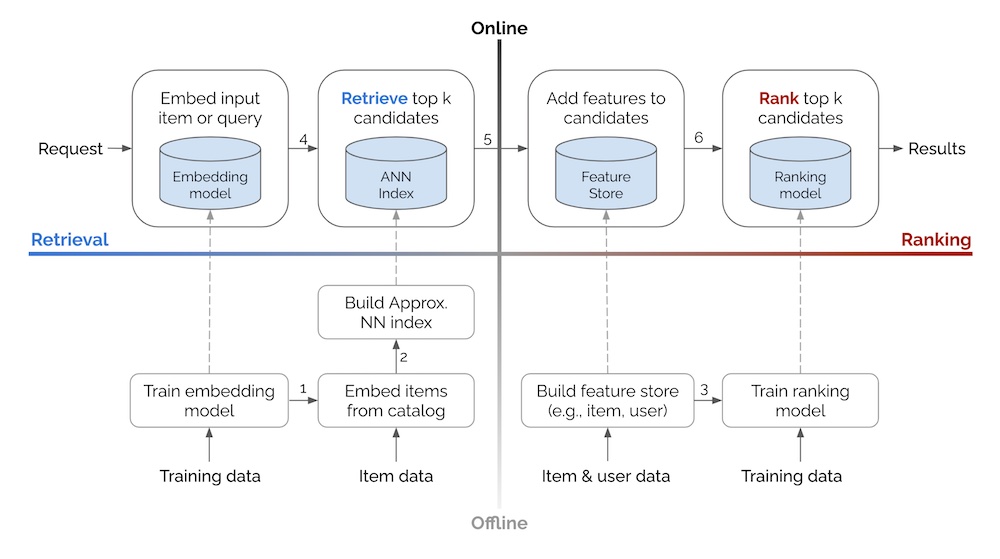 위의 2 x 2를 바탕으로 한 기본적인 추천과 검색 시스템 디자인.
위의 2 x 2를 바탕으로 한 기본적인 추천과 검색 시스템 디자인.
Offline 환경에서 데이터는 아래에서 위로 흐릅니다. 학습 데이터와 아이템/유저 데이터를 사용해서 모델이나 ANN indices, feature store 같은 artifacts를 만듭니다. 이런 artifacts는 온라인 환경에서 점선을 통해 load됩니다. Online 환경에서는 request가 왼쪽에서 오른쪽으로 흐릅니다. 추천이나 검색 결과를 만들기 전에 retrieval과 ranking 단계를 거칩니다.
다이어그램에서 숫자가 있는 화살표에 대한 세부 사항입니다:
- 학습된 representation learning 모델을 이용해 카탈로그에 있는 아이템들을 임베딩합니다.
- 아이템 임베딩을 사용하여 유사한 임베딩과 각각의 아이템을 찾을 수 있게 하는 ANN index를 만듭니다.
- (historical) 피쳐를 가져와서 ranking 모델 학습에 사용할 데이터를 augment합니다. train-serve skew를 최소화하기 위해 오프라인 학습과 온라인 서빙에 같은 feature store를 사용합니다. Time travel이 필요할 수도 있습니다. (역자주: 예를 들어 학습하는 시점에서는 아이템의 조회수가 10,000인데 유저-아이템 인터랙션이 발생한 시점의 조회수는 10이었다면 조회수 feature를 10으로 변경하여 학습에 사용하는 식의 조정을 말합니다.)
- 인풋 쿼리 또는 아이템 임베딩을 사용하여 ANN을 통해
k개의 비슷한 아이템을 찾습니다. - Ranking에 사용할 후보 아이템에 아이템과 유저 피쳐를 추가합니다.
- 클릭, 전환률 등등의 objective를 바탕으로 후보 아이템을 ranking합니다.
Examples from Alibaba, Facebook, JD, Doordash, etc.
다음으로, 논문과 기술 블로그를 기반으로 고수준의 탐색 시스템을 간략히 다뤄보겠습니다. 이들의 시스템이 어떻게 Online과 Offline 환경으로, Retreival과 Ranking 단계로 나뉘어지는지를 강조하려고 합니다. 방법론, 모델 등에 대한 자세한 내용은 전체 논문과 블로그를 읽기를 권합니다.
Alibaba의 candidate retreival을 위한 아이템 임베딩 설계에 대한 공유로 시작하겠습니다. Offline 환경에서, weighted, bidirectional 아이템 그래프를 구성하기 위해 세션 레벨의 유저-아이템 interaction이 사용되었습니다. 그래프는 아이템 random walk를 통해 sequence를 생성하는데 사용됩니다. 아이템 임베딩은 라벨이 필요 없는 representation learning(i.e, word2vec skip-grap)을 통해 학습됩니다. 마지막으로, 아이템 임베딩을 이용하여 각각의 아이템에 최근접 이웃을 구한다음 item-to-item(i2) 유사도 맵(i.e, a key-value store)에 저장합니다.
 알리바바의 아이템 임베딩과 ANN을 이용한 Taobao candidate retrieval 디자인
알리바바의 아이템 임베딩과 ANN을 이용한 Taobao candidate retrieval 디자인
Online 환경에서, 유저들이 앱을 실행할 때, 최근 상호작용(e.g., 클릭, 좋아요, 구매)을 일으킨 아이템들을 가져오면서 Taobao Personalization Platform (TPP)가 시작됩니다. 이 아이템들은 i2i 유사도 맵을 이용하여 후보를 retrieve하는데 사용됩니다. 후보들은 유저의 화면에 보이기 전에 Ranking Service Platform (RSP)에 전달되어 심층 신경망을 통해 ranking이 매겨집니다.
Alibaba는 그래프 네트워크를 랭킹에 적용한 비슷한 사례도 공유했습니다. offline 환경에서 기존 지식 그래프(G), 유저의 행동(e.g., 노출했을 때 클릭 여부), 아이템 데이터를 결합하여 adaptive knowledge graph (G_ui)를 만듭니다. 그런 다음 유저 데이터(e.g., demographics, 유저-아이템 선호도)를 병합하여 Ranking 모델(Adaptive Target-Behavior Relational Graph Network, ATBRN)을 학습합니다.
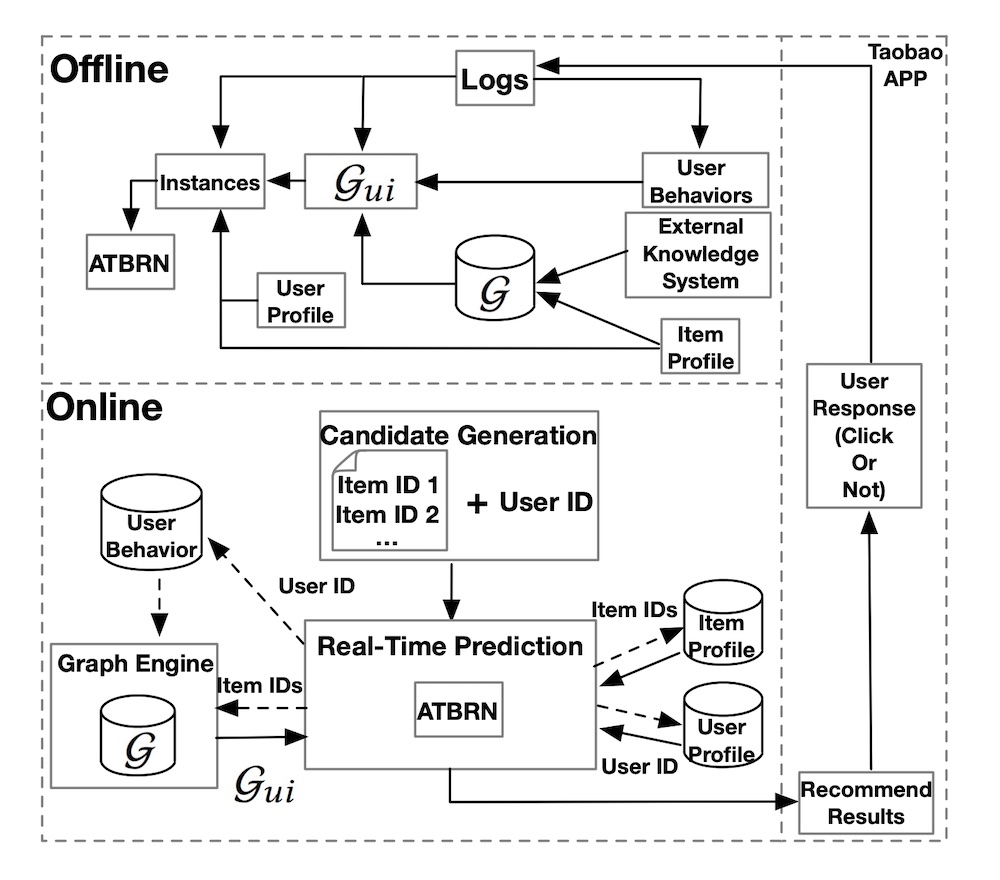 알리바바의 그래프 네트워크(ATBRN)을 이용한 Taobao ranking 디자인
알리바바의 그래프 네트워크(ATBRN)을 이용한 Taobao ranking 디자인
Online 환경에서, 유저의 request가 발생할 때, candidate generator는 후보 목록과 사용자 ID를 retrieve하여 Real-Time Prediction (RTP) 플랫폼에 전달합니다. 그런 다음 RTP는 지식 그래프와 feature store에서 아이템과 유저의 속성을 쿼리합니다. 다음으로 graph representation과 아이템 데이터, 유저 데이터가 ranking (i.e., ATBRN) 모델에 전달되어 각 후보 아이템에 대하여 클릭 확률을 예측합니다. 후보들은 확률 값을 기준으로 재정렬되어 유저에게 표시니다.
다음으로, Facebook의 embedding-based retrieval for search를 살펴보겠습니다. Offline 환경(이미지의 오른쪽 절반)에서는 먼저 two-tower 네트워크(쿼리 인코더와 문서 인코더로 구성)를 학습하여 각 쿼리-문서 쌍에 대해 코사인 유사도를 출력합니다(이 부분은 이미지에 표시되지 않았습니다). 이렇게 하면 검색 쿼리와 문서(예: 유저 프로필, 그룹)가 동일한 임베딩 공간에 있게 됩니다.
 Facebook의 쿼리와 문서 인코더를 통한 임베딩 기반 retrieval 디자인
Facebook의 쿼리와 문서 인코더를 통한 임베딩 기반 retrieval 디자인
그런 다음, 문서 인코더를 사용하여 Spark batch job을 통해 각 문서를 임베딩합니다. 임베딩은 quantized되어 ANN index(“역색인”)로 publish 됩니다. 이 ANN index는 Faiss를 기반으로 fine-tuned됩니다(논문의 4.1절을 참고). Ranking을 위한 forward index에서는 임베딩이 quantization없이 publish 됩니다. Ranking 중에 후보들을 augment하기 위하여 forward index는 프로필이나 그룹의 속성 정보를 포함할 수도 있습니다.
Online 환경에서, 각 검색 요청이 쿼리 이해를 거쳐서 쿼리 인코더를 통해 임베딩됩니다. 검색 요청과 관련 임베딩은 retrieval 단계를 거치는데 ANN과 boolean 필터링(e.g., 제목, 지리 등등과 일치 여부)을 통해 최근접 이웃 후보를 얻습니다. 그런 다음 후보들은 전체 임베딩과 forward index에서 얻은 추가데이터가 augment된 후에 ranked됩니다.
JD는 semantic retrieval for search에서 비슷한 접근을 공유했습니다. Offline 환경에서, 쿼리 인코더와 아이템 인코더로 이루어진 two-tower 모델이 각 쿼리-아이템 쌍에 대해 유사도 점수를 아웃풋으로하여 학습됩니다. 아이템 인코더는 임베딩 인덱스(i.e, key-value store)에 적재되기 전에 카탈로그 아이템들을 임베딩합니다.
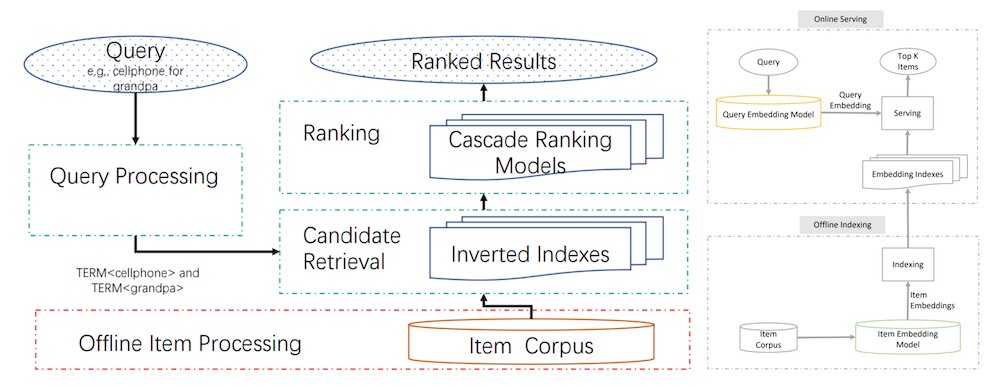 e-commerce 검색 시스템의 주요 단계 (왼쪽), candidate retrieval을 위한 JD의 설계 (오른쪽).
e-commerce 검색 시스템의 주요 단계 (왼쪽), candidate retrieval을 위한 JD의 설계 (오른쪽).
그런 다음, Online 환경에서, 각 쿼리는 쿼리 인코더를 통해 임베딩되기 전에 전처리(e.g., 철자 보정, 토큰화, 확장, 재작성)를 거칩니다. 쿼리 임베딩은 최근접 이웃 룩업을 통해 임베딩 인덱스에서 후보를 retrieve할 때 사용됩니다. 후보는 관련도, 예상 전환률 등등의 요소에 의해 rank 됩니다.
논문에서는 모델 학습과 서빙을 최적화하기 위한 실용적인 팁도 공유합니다. 모델 훈련시에, 유저-아이템 상호작용, 아이템 데이터, 유저 데이터로 이루어진 인풋에서 사실상 중복이 많고 아이템과 유저 데이터가 row 마다 나타나 상당한 디스크 공간을 소비한다고 주장했습니다. 이 문제를 해결하기 위해, 유저와 아이템 데이터가 먼저 메모리에 적재되어 룩업 사전으로 이용하는 custom Tensorflow dataset을 만들었습니다. 그런 다음 학습 중에, 학습 데이터의 유저와 아이템 속성을 추가할 때 사전이 쿼리됩니다. 이런 간단한 방법으로 학습 데이터의 크기가 90% 감소했습니다.
또한 논문에서는 오프라인 학습과 온라인 서빙의 일치성을 보장이 중요하다고 강조했습니다. 그들의 시스템에서, 가장 중요한 단계는 세 번 발생하는 텍스트 토큰화(전처리시, 학습시, 서빙시)입니다. train-serve skew를 최소화하기 위해, 모든 토큰화 작업에서 thin 파이썬 래퍼로 C++ 토크나이저를 구축했습니다.
모델 서빙시에 서비스를 결합하여 어떻게 latency를 줄였는지 공유했습니다. 모델에는 쿼리 임베딩과 ANN 룩업이라는 두 가지 중요한 단계가 있습니다. 쉬운 방법은 각각을 별도의 서비스로 갖는 것이지만 두 번의 네트워크 호출이 필요하다는 뜻이고 네트워크 latency도 두 배가 된다는 뜻입니다. 그래서 그들은 쿼리 임베딩과 ANN 룩업을 하나의 인스턴스에 결합하여 쿼리 임베딩을 네트워크 대신에 메모리를 통해 ANN으로 전달합니다.
또한 서로 다른 retrieval 작업과 다양한 A/B 테스트를 위해 수 백개의 모델을 어떻게 운영했는지도 공유했습니다. 각각의 “servable”은 쿼리 임베딩과 ANN 룩업으로 구성되고 수십GB가 필요합니다. 그러므로 각각의 servable은 요청을 적절한 servable로 지시하는 프록시 모듈(또는 로드 밸런서)과 함께 각각의 인스턴스를 갖추고 있습니다.
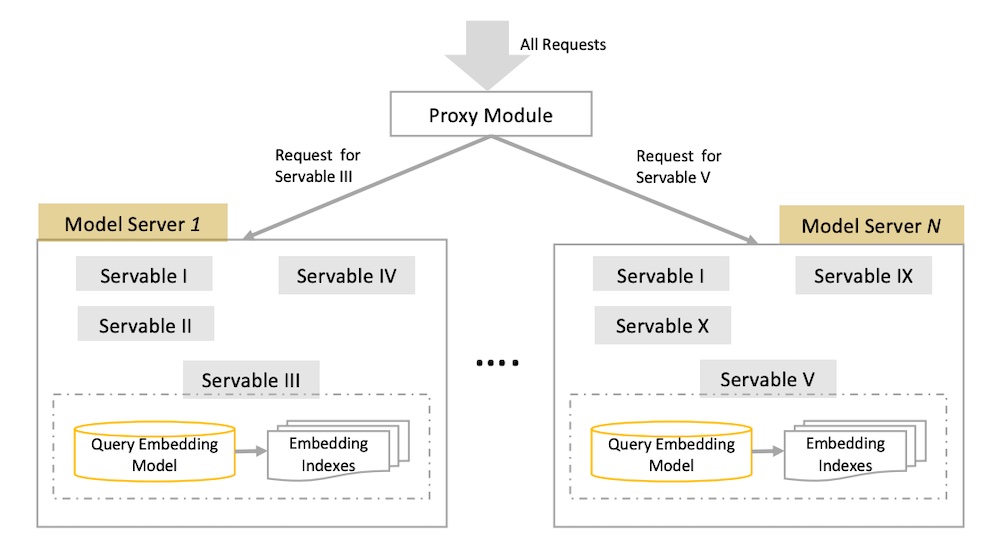 JD가 임베딩 모델과 ANN 인덱스를 여러 버전에서 구성하는 방법.
JD가 임베딩 모델과 ANN 인덱스를 여러 버전에서 구성하는 방법.
(여담: 저의 candidate retrieval 시스템도 비슷한 디자인 패턴을 갖고 있습니다. 임베딩 저장소와 ANN 인덱스들은 같은 도커 컨테이너에 호스팅되는데 효율적인 크기의 임베딩과 얼마나 많이 함께 동행할 수 있는지 놀랄 것입니다. 게다가 도커는 버저닝, 배포, 각 모델의 롤백, 수평적 확장에 용이합니다. 모델 인스턴스 앞에 로드 밸런서를 붙이면 들어오는 요청을 지시할 수 있고, 블루-그린 배포, A/B 테스트를 관리할 수 있습니다. SageMaker가 이런 작업을 쉽게 만듭니다.)
다음으로, 임베딩 + ANN 패러다임을 벗어나 DoorDash의 knowledge graph for query expansion and retrieval를 살펴보겠습니다. Offline 환경에서, 그들은 쿼리 이해, 쿼리 확장, Ranking 모델을 학습합니다. 또한 retrieval 용도로 ElasticSearch에 문서(i.e., 식당과 음식 아이템들)를, feature store에 속성 데이터(e.g, 평점, 가격대, 태그)를 로드합니다.
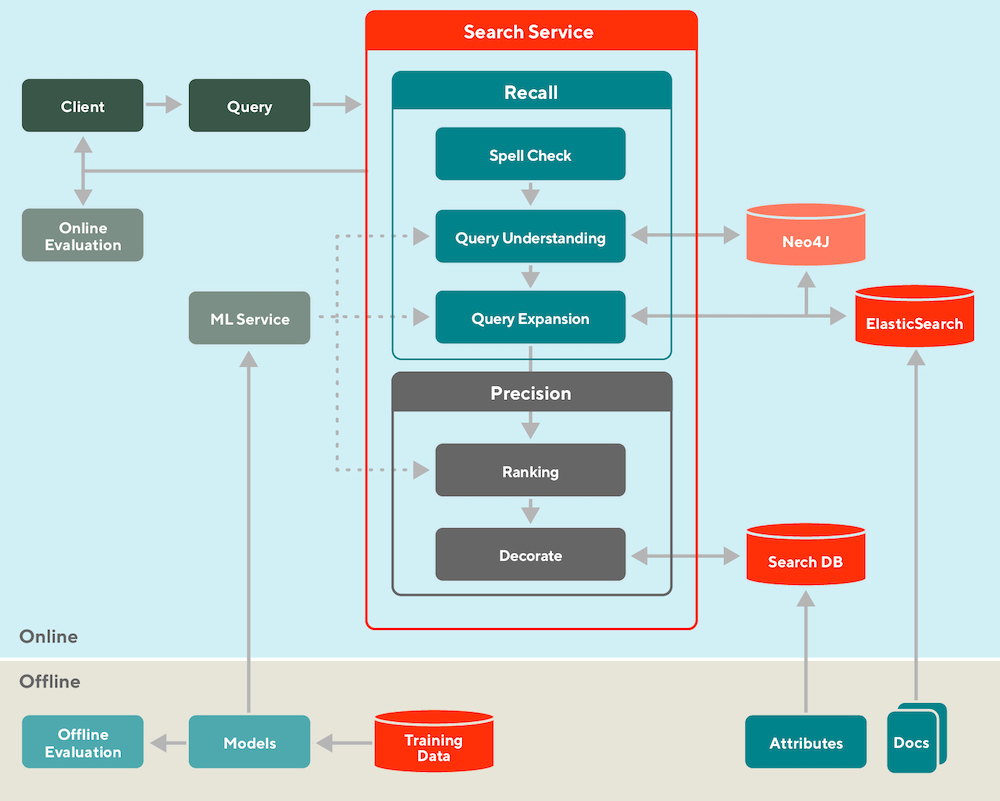 DoorDash는 검색을 오프라인과 온라인, retrieval(recall)과 Ranking(precision)으로 나눈다.
DoorDash는 검색을 오프라인과 온라인, retrieval(recall)과 Ranking(precision)으로 나눈다.
Online 환경에서, 들어오는 쿼리를 먼저 표준화(e.g., 철자 검사)하고 동의어 처리(수작업된 사전을 통해)합니다. 그런 다음, 지식 그래프(Neo4J)가 관련된 태그를 찾아 쿼리를 확장합니다. 예를 들어, “KFC” 같은 쿼리는 “후라이드 치킨”과 “날개뼈” 같은 태그를 반환합니다. 그리고 나서 이 태그들은 “파파이스”나 “Bonchon” 같은 비슷한 식당을 retrieve하는데 사용됩니다.
이런 후보들은 쿼리와 문서(레스토랑, 음식 아이템들)의 어휘적 유사성, 매장 인기도 및 검색 맥락(e.g., 시간대, 위치)을 기준으로 Ranked 됩니다. 마지막으로, 순위가 매겨진 결과들은 유저의 화면에 보여지기 전에 평점, 가격대, 배달 시간 같은 속성들과 결합됩니다.
마지막으로 LinkedIn의 personalizes talent search results를 살펴보겠습니다. 그들의 시스템은 XGBoost에 많이 의존하고 있습니다. 하나는 Ranking을 위한 top 1,000개의 후보를 retrieve하는 모델로, 다음으로는 downstream Ranking 모델(GLMix로 불리는 a generalized linear mixed model)의 피쳐(i.e., 모델 스코어, 트리와 상호작용) 생성자로 사용합니다.
 트리 기반 피쳐의 생성과 GLMix Ranking 모델 학습을 위한 LinkedIn의 오프라인 디자인
트리 기반 피쳐의 생성과 GLMix Ranking 모델 학습을 위한 LinkedIn의 오프라인 디자인
Offline 환경에서, 그들은 impression과 라벨 데이터를 결합해 학습 데이터를 생성합니다(위 그림에서 1단계). 라벨은 리크루터가 잠재적 채용자에게 보내고 유저가 긍정적으로 대답한 데이터로 구성합니다. 그런 다음 학습 데이터를 pre-trained XGBoost 모델에 넣어 모델 스코어와 트리 상호 작용 피쳐를 만들어 학습 데이터에 augment합니다. 이렇게 augmented 데이터는 Ranking 모델(GLMix)에 사용됩니다.
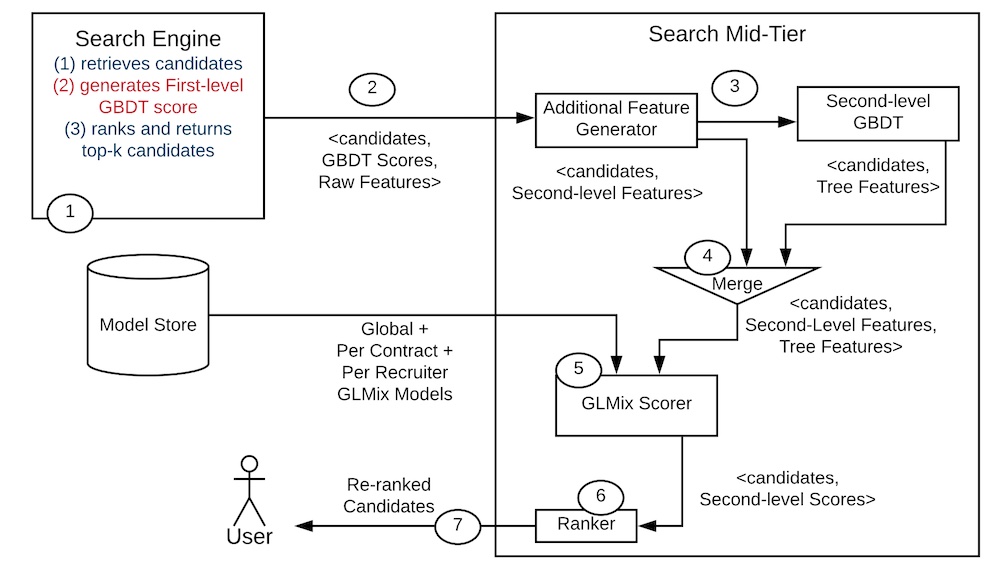 LinkedIn’s online design for candidate retrieval, feature augmentation, and ranking via GLMix.
LinkedIn’s online design for candidate retrieval, feature augmentation, and ranking via GLMix.
Online 환경에서 검색 요청이 오면, 먼저 검색 엔진(아마도 Elastic 이나 Solr?)이 1차 XGBoost 모델에서 점수를 매길 후보들을 retrieve 합니다. 상위 1,000개의 후보는 (i) 추가 피쳐들(위 그림에서 2단계)과 (ii) 2차 XGBoost 모델을 통한 트리 상호작용 피쳐들로 augment됩니다. 마지막으로, 이런 augment된 후보들은 순위가 매겨져서 125개의 결과가 유저에게 보여집니다.
Conclusion
검색과 추천을 위한 Offline-Online, Retrieval-Ranking pattern의 간략한 개괄이었습니다. 탐색 시스템을 위한 유일한 접근법은 아니지만, 제가 보기엔 가장 일반적인 디자인 패턴입니다. latency 제약이 있는 온라인 시스템과 그런게 덜 요구되는 오프라인 시스템을 구분하고 온라인 과정에서 retrieval과 ranking 단계를 나누는게 도움이 된다는 점을 알게 되었습니다.
탐색 시스템을 만들기 시작하고 있다면 Ranker를 추가하기 전에 candidate retrieval via simple embeddings and approximate nearest neighbors로 시작해보세요. 또는, Uber나 DoorDash처럼 지식 그래프를 사용하는 걸 고려해보세요. 그러나 너무 들뜨기 전에 정말 실시간 Retrieval과 Ranking이 필요한지 아니면 batch recommendation으로 충분할지 충분히 고민해 보세요.
Eugene Yan의 원글을 허락받아 번역한 글입니다.
글을 바탕으로 발표한 영상도 참고해보세요.
References
- Billion-scale Commodity Embedding for E-commerce Recommendation
Alibaba - Adaptive Target-Behavior Relational Graph Network for Recommendation
Alibaba - Embedding-based Retrieval in Facebook Search
Facebook - An End-to-End Solution for E-commerce Search via Embedding Learning
JD - Things Not Strings: Understanding Search Intent with Better Recall
DoorDash - Entity Personalized Talent Search Models with Tree Interaction Features
LinkedIn - Faiss: A Library for Efficient Similarity Search
Facebook
You might also like
- Search: Query Matching via Lexical, Graph, and Embedding Methods (4 months ago)
- Bootstrapping Labels via ___ Supervision & Human-In-The-Loop (1 month ago)
- NLP for Supervised Learning - A Brief Survey (1 year ago)
- Patterns for Personalization in Recommendations and Search (3 months ago)
- DataTalksClub - Building an ML System; Behind the Scenes (7 months ago)