
21년에 열린 추천 시스템 관련 대회와 NVIDIA의 솔루션을 정리합니다,
Introdcution
올해 WSDM, SIGIR, RecSys 학회에서 추천시스템 Challenge가 열렸습니다. 각각 Booking.com의 호텔 예약 데이터, Coveo의 E-commerce 데이터, Twitter의 SNS 데이터를 활용했습니다. NVIDIA는 Kaggle Grandmaster, Rapids.ai, Merlin 멤버들이 팀을 이뤄 위 대회에 참가하여 좋은 성적을 거두었습니다. 대회에서 사용한 솔루션을 논문, 영상, 글, 코드 등등으로 공유하고 있습니다. Challenge와 NVIDIA의 Solution을 간략하게 정리하여 소개합니다. 순서는 대회 날짜순입니다만 우연히도 난이도, 데이터셋 크기 순서이기도 합니다.
Booking.com Multi-Destination Trips Dataset, WSDM WebTour’21
키워드 : Trip, Session-based Matrix Factorization(SMF), XLNet
 출처: booking.com
출처: booking.com
Booking.com은 여행자들이 교통편, 다양한 숙소, 특별한 투어, 액티비티 등등을 간편하게 예약할 수 있는 서비스입니다. 유저가 여행하는 동안 예약한 호텔 출입 데이터가 최소 4개 이상 주어졌을 때 마지막으로 예약한 호텔의 도시를 맞추는 대회입니다. Precision@4를 주요 Metric으로 활용했습니다. 1M개 정도의 Reservation 데이터가 있습니다.
FE에서는 여행 도메인이다보니 지역 정보와 시간 정보를 활용한 처리가 많았습니다. 여행 순서를 reverse하는 augmentation 기법도 사용했네요. (서울 → 대전 → 대구 → 부산) 데이터를 (부산 → 대구 → 대전 → 서울) 방식으로도 활용하는 식입니다.
Modeling에서는 Session-based Matrix Factorization(SMF)를 제안했습니다. 기존의 MF가 user와 item의 Latent vector를 dot product했다면 SMF는 Session(여행)과 City를 dot product하는 방식입니다. Session을 Embedding하는 방법으로는 MLP, GRU, XLNet을 사용했습니다. Output을 낼 때는 NLP에서 유래한 Tying Embedding을 사용했습니다. item embedding table을 output layer에도 사용하는 테크닉입니다.
Booking.com 대회는 아래 두 대회와 비교하면 데이터셋이 작고(= 컴퓨팅이 많이 필요하지 않고), Task도 간단해서 입문하기 좋아보입니다.
대회 페이지, 데이터(대회 페이지 안에 있습니다), 페이퍼, 설명 영상, 코드
In-session prediction for purchase intent and recommendations, SIGIR eCom’21
키워드 : E-Commerce, Multi-Modal, Cart Abandonment, Augmentation, Transformer-XL, DLRM
Coveo는 검색, 개인화, 추천 기능을 클라우드 기반으로 제공하는 SaaS 기업입니다.
Task는 1)추천과 2)구매 의향 파악 두 가지입니다. 1) 추천 태스크는 e-commerce 서비스에서 세션이 주어졌을 때 다음 아이템을 예측하는 태스크로 MRR을 주요 Metric으로 사용했습니다. 2) 구매 의향 파악은 ‘장바구니’ 추가 이벤트가 발생했을 때 유저가 장바구니에 추가한 아이템을 구매할지 안할지를 예측하는 태스크로 Micro F1을 Metric으로 사용했습니다. 36M개의 Event Data가 있습니다.
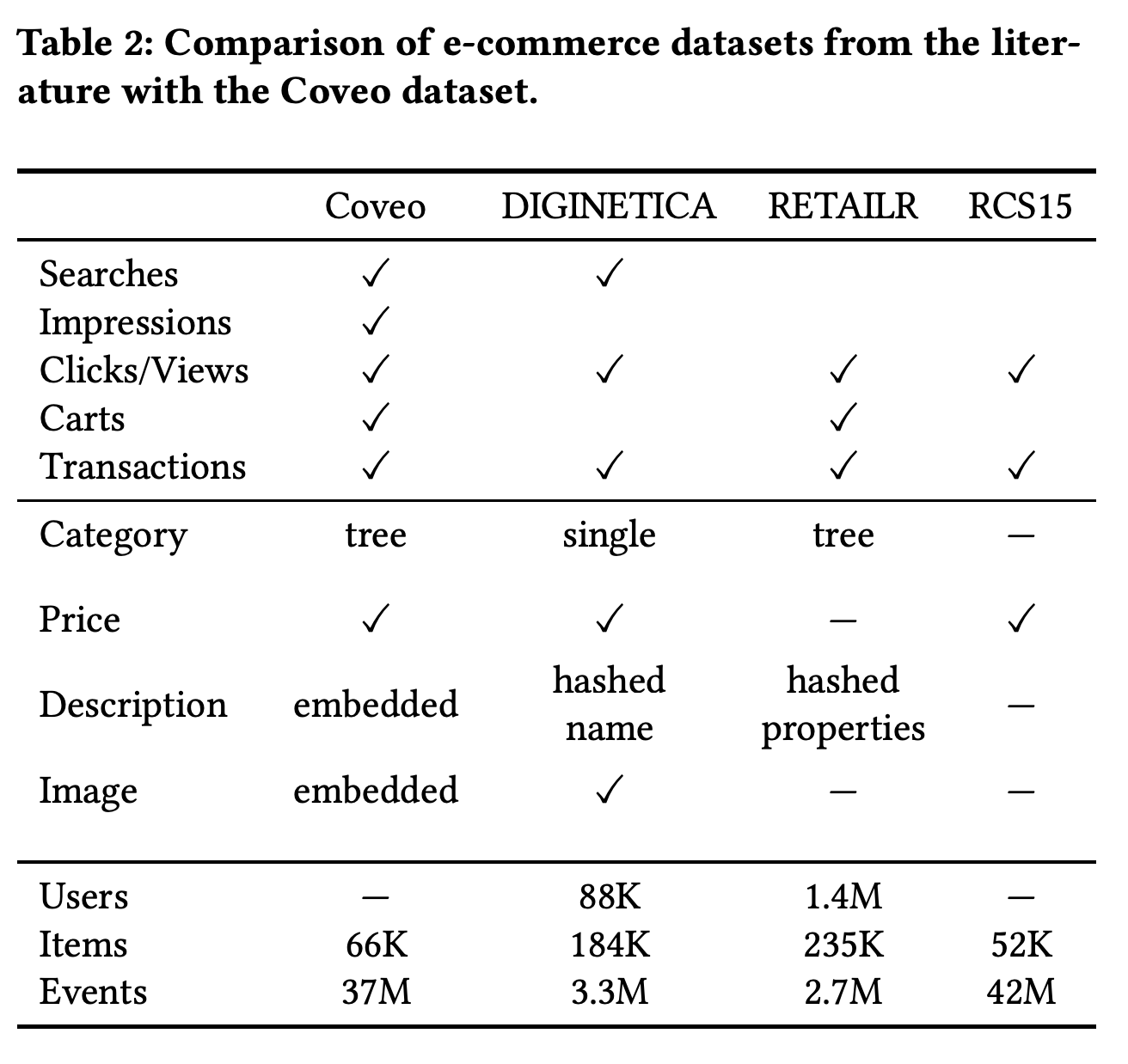
Coveo는 아래 그림과 같이 이전에 공개된 e-commerce 데이터들과 자신들이 제공하는 데이터의 차이점을 강조하고 있습니다. 세션 내의 검색 기록과 조회된 상품 이미지를 pre-trained embedding vector로 제공, Click 뿐만 아니라 Impression까지 같이 제공, 장바구니 추가 event 제공, 카테고리를 소분류까지 카탈로그 형식으로 제공하는 정도가 특징으로 볼 수 있습니다.
NVIDIA팀은 제공된 데이터를 최대한 활용(Non-product page view, Search Click Event를)하여 Session 데이터를 Augemnet했습니다. 이외에도 중복되는 event 제거, Unpopular Product 제거 같은 FE가 있었습니다.
추천 태스크 Modeling에서는 1) Product Description, Search, Image Vector 같은 Multi-Modal Feature들을 어떻게 모델에 반영하는지 2) Context Feature를 어떻게 모델에 반영하는지가 중요했습니다. 기존의 연구 결과를 바탕으로 Multi-Modal Feature는 L2-normalization을 활용했고 Context Feature는 Prediction Vector와 Latent Cross했습니다. 모델 구조로는 Transformer-XL, XLNet을 사용했습니다.
[뜬금 스터디 모집 홍보] 이 글에서 소개한 대회들을 바탕으로 스터디를 진행하려고 합니다. 자료를 같이 보면서 의견을 나누고 공개된 코드를 실행해보면서 구현을 뜯어보려고 합니다. 관심있으신 분은 구매 의향 파악 Task의 Feature Engineering 전략과 모델링 방식을 간단하게 정리해서 저에게 페이스북 메시지나 카카오톡(아이디: 571219) 보내주시면 됩니다! 참고 자료(https://bit.ly/3A2JF3e). 시간은 화요일 8시이고 스터디 방식은 발표보다는 의견 교환, 궁금한 점 토론 위주로 진행할 생각입니다. 자세한 사항은 메시지 보내주시는 분들에게 다시 안내하겠습니다.
Tweet engagement prediction, RecSys Challenge’21
키워드 : SNS, Fairness, NLP, Computing Optimization, Sparse Embedding, Target Encoding with Smoothing, Stacking
트위터는 많이들 아시겠지만 페이스북과 비슷한 SNS 서비스입니다.
이 대회의 Task는 유저에게 트윗이 주어졌을 때 어떤 Engagement가 발생할지 예측하는 문제입니다. 1Billion 정도의 Engagement 데이터가 있습니다.
Engagement의 종류로는 Retweet, Reply, Like, Retweet with comment가 있습니다. 페이스북으로 치면 유저A가 유저B의 글을 보았을 때 공유하기를 할지, 댓글을 달지, 좋아요를 누를지, 공유하기 후에 유저 A가 글을 덧붙일지 정도로 비유할 수 있습니다. Metric으로는 Average Precision(AP)와 Relative Cross Entropy(RCE)를 Popularity Fairness를 고려하여 측정했습니다.
이 대회는 20년에 개최된 RecSys Challenge와 상당히 유사한데요. 이때도 Twitter에서 같은 Task로 Challenge를 열었습니다. 달라진 점이 있다면 1) Fairness 2) Limited Computation입니다.
- Faireness: Metric을 측정할 때 모든 Test Set을 Overall Average해서 측정하는 대신 Popularity를 기준으로 게시자를 나눠서 구간마다 측정합니다. 예를 들어 팔로워가 1M인 사람의 글, 1K인 사람의 글, 50명인 사람의 글이 다른 Category에 나눈 다음 따로따로 나눠서 Metric을 계산합니다. 팔로워가 많은 사람의 글이든 적은 사람의 글이든 구분 없이 예측 성능이 좋기를 기대하는 주최측의 바람이 있습니다.
- Limited Computation: 보통의 대회는 Inference 값을 제출하여 Metric만 주최측에서 계산하여 순위를 매깁니다. 이 대회에서는 이런 방식 대신에 코드와 모델을 주최측 서버에 제출합니다. 코드와 모델의 용량은 20GB로 제한되어 있고 Computing Power는 GPU없이 1CPU, 64GB RAM (!!!)으로 제한되어 있으며 Test Set Inference를 24시간 내에 수행할 수 있어야합니다. Test Set에는 15M의 데이터 포인트가 있기 때문에 데이터 한 개당 6ms보다 빠른 시간 내에 Inference를 할 수 있어야 하는 것입니다. 실제 서빙에서 사용할 수 있는 모델을 제출하기를 기대하는 주최측의 바람이 있습니다.
NVIDA의 Solution에서는 Computing을 Optimization하기 위한 노력이 많이 엿보였습니다. 방금 한 말과 모순되어 보이지만 3개의 Neural Net과 5개의 XGBoost를 Ensemble Stack 한 솔루션입니다. 처음엔 의아했는데 제시된 Computing Limitation을 지켰으니 속도상 문제가 없을 것 같고 오히려 Optimization을 얼마나 잘했는지 실감할 수 있는 부분입니다.
모델을 크게 세 가지로 분류할 수 있습니다. 1) Stage1의 Neural Net부분 2) Stage1의 XGBoost 부분 3) Stage2의 XGBoost 부분입니다. Stage는 Validation Set 공개 이전, 이후의 모델입니다. 나눠서 간략하게 살펴보겠습니다.
- Stage1의 Neural Net부분 : Text Data와 User Embedding, Continuous feature의 상호작용을 종합해서 모델링했습니다. Text Data를 처리하는 부분에서는 Tweet의 앞 48token만 multilingual Bert의 Word Embedding을 이용해서 Embedding한 다음 Single layer GRU로 처리했습니다. User Embedding에서 특히 Optimization Trick이 많습니다. 이용자이면서도 게시자일 수 있기 때문에 Jointly Embedding/ Interaction이 적은 User는 같은 유저로 취급(Progressive 하게 Threshold를 낮춤)/ Pytorch의 sparse embedding 활용/ 20M Embedding Table을 10M Table 둘로 나눠서 처리 등등…
- Stage1의 XGBoost: XGBoost는 Categorical Feature를 잘 handle하지 못하기 때문에 User Feature를 Neural Net과 같은 방식으로 처리하지 못합니다. 대신 Target Encoding(TE)를 사용했고 Smoothing처리를 곁들였습니다. Stage1에서는 3개의 XGBoost 모델이 있는데 각 모델마다 TE 방식과 텍스트 데이터를 쓰느냐 안쓰느냐 같은 feature가 조금씩 다릅니다. Fairness에 의해 분류된 User Group마다 따로따로 모델을 학습했습니다.
- Stage2의 XGBoost: 대회 종료 2주 전에 대회 측은 Validation Set을 Label과 함께 공개합니다. 참가팀들은 추가로 확보된 데이터를 어떻게 Leveraging할지 고민해야 했습니다. 이런 Setting은 실제 추천 상황에서 이미 학습된 모델이 있고 새로운 데이터가 추가되었을 때 어떻게 이 데이터를 활용할지 고민하는 상황을 고려해서 만든 것으로 추측됩니다. NVIDA팀은 Continual Learning, Retraining을 하기 보다는 Stacking을 선택했습니다. Train Data로 학습된 모델의 Prediction과 Feature Engineering과 새로 생긴 Valid Dataset을 Feature Engineering하여 최종으로 XGBoost 모델 두 개를 추가로 학습하여 Test Set을 Inference했습니다.